So, in my last post I made a case for leaving automatic error handling turned on. I also made the statement:
To be clear, what I’m /not/ saying is that you should USE automatic error handling. That’s a pretty bad idea; you should always do proper error handling.
So what’s the difference? If you’re intentionally not wiring your error terminal to something and you have automatic error handling turned on, then you’re choosing to invoke automatic error handling. As an example of a particularly bad choice, consider the following:

In case the above isn’t obvious, it’s not uncommon to get a timeout (Error 56) on a TCP read. What you don’t want is a modal dialog that causes your program to abort execution every time you get said timeout. So, you say, since we’re not turning off automatic error handling, what should we do?
I’m glad you asked! In short, we need to wire the output error terminal to the input of something. We have a few options here.
The Flat Sequence Structure

Here we have one of the simplest possible solutions: wire it to the edge of a Flat Sequence Structure. This is an input to a tunnel, and, therefore scrubs the error. Now, this is indiscriminate and doesn’t actually give provisions for “handling” the error per se, but it does keep it from popping the automatic error handling dialog. If you are absolutely, positively certain that you will never get any errors on that wire that you would want to pay attention to, then this is a viable solution for you. In this case, however, I’d suggest we keep looking for a better option.
The Case Structure (Error Structure)
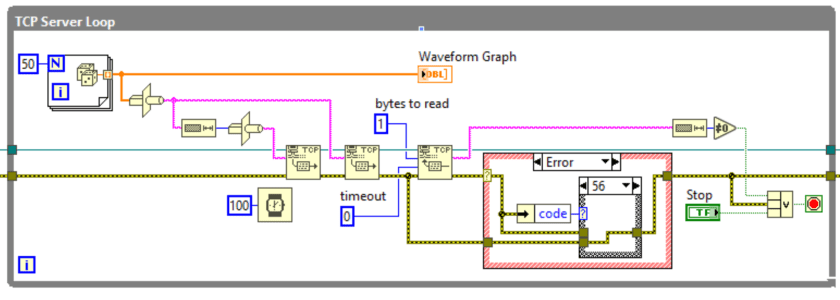
One option is to use our friendly neighborhood case structure, often referred to as an “error structure” when wired in this manner. This gives us the option of doing something different in the case of a timeout. (For clarity, the “no error” case is wired straight across the top. The only other case in the inner case structure is “default,” which wires the top error through.)
As implemented, what this does is throw away an error 56, specifically from the immediately preceding TCP Read function; it passes along any errors that occurred within this function or that occurred further upstream.
Clear Errors
This, in my mind, is the cleanest method. Functionally, it is doing the exact same thing as our previous case structure; to me, however, it is much more obvious what this is doing.
Worth noting, it’s actually doing something similar under the hood as well. Here’s the diagram of “Clear Errors” for reference:
Finally, as the label indicates, we can pass in zero for our specific error code (or just leave it unwired), and it will clear all of the errors. For those few cases where that is rational, for the sake of readability I usually prefer this over the Flat Sequence Structure referenced above, however both are certainly viable options.
Good start point, OK for use ignore error. But can you add in second part, the state machine and manage the error in one case, to allow function for what’s do in error?
IN your sample state machine allow you, not only to ignore but solve other error like 63, 64 then you can manage for reconnect if client or server disconnect.
Nicola, I agree that handling other errors in that case structure would be a great idea; I was just trying to focus specifically on methods of ignoring instead of general handling of errors. I’ll take this in to consideration for a future post.
In the Clear Errors example, you may want to swap the Merge Error input terminals to prioritize upstream errors. As the code stands now, it will clear error 56 from that TCP Read AND any upstream error 56s, which you may want to know about. Swapping the Merge Error terminals will effectively only clear error 56 from the TCP Read.
Hey sorry for taking so long to approve this comment.
I agree that my terminals on the merge should be flipped to prioritize upstream errors, but I’m not sure that understand your point of it clearing the error completely… as I see it, the upstream error 56 would still be merged back in on the bottom terminal even if it’s cleared on the top.
Am I missing something?